SSD筆記 - 第五篇 access pattern, 系統配置
SSD 學習筆記,翻譯與修訂自 http://codecapsule.com/2014/02/12/coding-for-ssds-part-6-a-summary-what-every-programmer-should-know-about-solid-state-drives/
前情提要
作者在介紹了 SSD 內部運作原理後,為何同時 (concurrent) 進行的讀寫行為會互相干涉,並介紹如何更好的 SSD 讀寫手法。此篇也涵蓋了一部分可改善效能的檔案系統最佳化手段。
7 Access Patterns
7.1 定義循序及隨機 IO 操作
Sequential/循序:一個 IO 操作的 LBA / Logical block address 開頭接著上一個操作 LBA 的結尾。除此之外皆視為隨機。 值得注意的是即便我們 LBA 是連續的,經過 FTL 之後實際存在 physical block 的資料還是可能會四散各處。
7.2 寫
效能評定報告及廠商規格通常會顯示循序寫入速度慢於隨機寫入。
但作者這類資料是用小於 clustered block size 的資料量(< 32 MB)的測試,沒用到平行機制。如果大於還剛好是倍數,寫入的效能是可以比擬的。作者的解釋是 parallelism 跟 interleaving 同時上場,也就是寫入一個 clustered block 可以保證 SSD 完全用上了設計好的機制。下兩圖分別是從 [2, 8] 擷取出來,隨機寫入效率跟循序寫入在寫入資料大小跟 clustered block 差不多大的時候是差不多的(大約是 16/32 MB)。
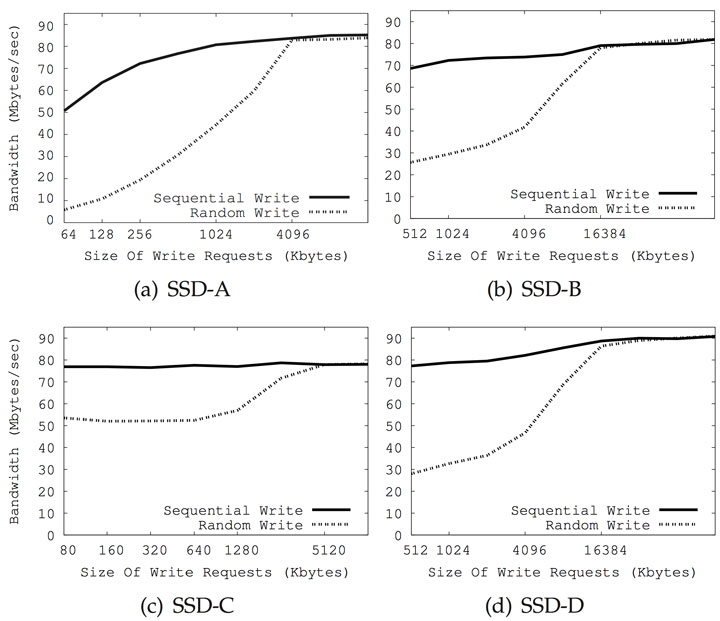
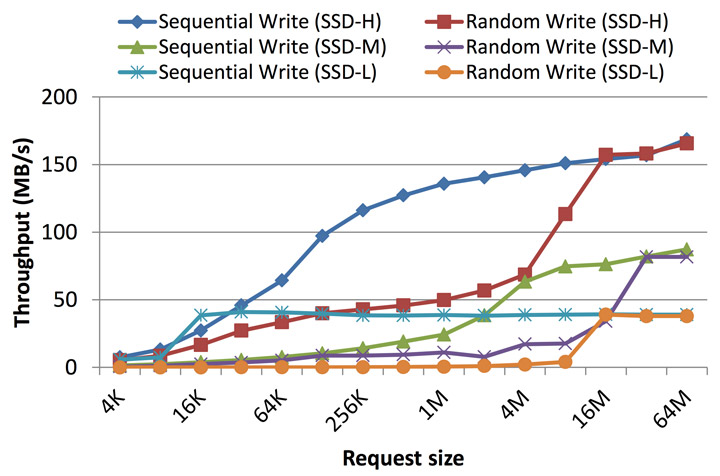
然而當隨機寫入小於 page size 如 16 KB 的資料時,除了寫入放大,SSD 工作量也會變多,例如必須要把每一筆 LBA 對應的 PBA mapping 都記錄下來,而許多 FTL 用類似 tree 之類的資料結構來存,很多的小資料寫入會變成對 FTL RAM 的大量更新操作,而且這個 mapping table 必須在斷電後留存 / persisted ,結果就是同時帶來對 nand block 的大量寫入 [1, 5]。 循序寫入可以降低此類更新 metadata 的情形發生,減少對 flash 的寫入。
隨機大量小資還會造成大量 copy-erase-write 的現象發生。相較 循序寫入至少一個 block 大小的資料的情況,switch merge 等 happy path 更容易在後者發生。隨機大量小資還會讓 stale page 四散在各個 block,而不是集中在某個區域。這現象也稱為 internel fragmentation,造成 cleaning efficiency / 清掃效率降低, GC 需要搬動更多次資料來清除一樣大的空間。
至於應用層關心的 concurrency , 單執行緒的大筆資料寫入與多執行緒的同步多筆寫入差不多快,而且前者較能利用到 SSD 的平行處理機制,因此費工夫寫多執行緒的寫入並不會對 IO 的效能有幫助[1,5],反而有害[3, 26, 27]。
但是作者最後備註還是寫了如果你沒辦法把隨機大量小資做緩存批次寫入,還是用多執行緒會比較快。
7.3 讀
總的來說,讀比寫快。但循序跟隨機讀取孰快孰慢,不一定。FTL 在寫入時動態的/ dynamically 將 LBA 寫到 PBA 去,其中更涉及上述的平行機制,資料切塊寫到各個 channel/package 去,這個寫入模式也稱為 “write-order-based” [3]。如果讀取的順序完全隨機,跟寫入模式無相關,則讀取時先前以平行機制寫入的資料不保證在讀取時有用。很多時候即便 LBA 是連續的,讀取效能也不一定好,甚至連續的 LBA 讀取被 mapping 到同一個 channel 上,還是要排隊等資料。作者提到 Acunu [47] 有篇 blog 測試發現讀取資料的模式與寫入的模式有直接關聯。
[47] 的 Acunu 網站已經掛了。[TODO]: 找替代方案
讀取效能與寫入模式息息相關,作者建議相關聯的資料最好寫在同個 page / block / clustered block 裡,確保寫入時用到平行機制,相關聯資料放一起也較符合日後讀取需求與效能提升條件。
下圖是 2 channels, 4 chips, 1 plane/chip 的參考配置圖。注意通常一個 chip 裡面不只有一個 plane,作者做了些簡化以便說明。大寫的英文字分別代表一筆 NAND-flash block 大小的資料。這裡我們寫入四筆連續的 LBA 資料 [A, B, C, D],剛好也是 clustered block 的大小。利用 clustered block 平行機制(parallelism and interleaving)這四筆資料會被分開寫到四個 plane 去。即便他們在 logical address 是連續的,為了效能考量他們會被分到不同的 physical plane。
write-order-based FTL 在選擇寫入 clustered block 的時候不會要求在各 plane 的 PBN 要相同,所以圖例可以看到 結果寫到了 1, 23, 11, 51 這四個位置去。
我不太確定作者提這個用意為何,先前他也沒有介紹 plane 的設計細節 XD
當我們讀取 [A, B, E, F], [A, B, G, H] 的時候,前者因為部分資料在同個 plane 裡,需要讀兩次,後者則可利用到平行機制加快讀取。
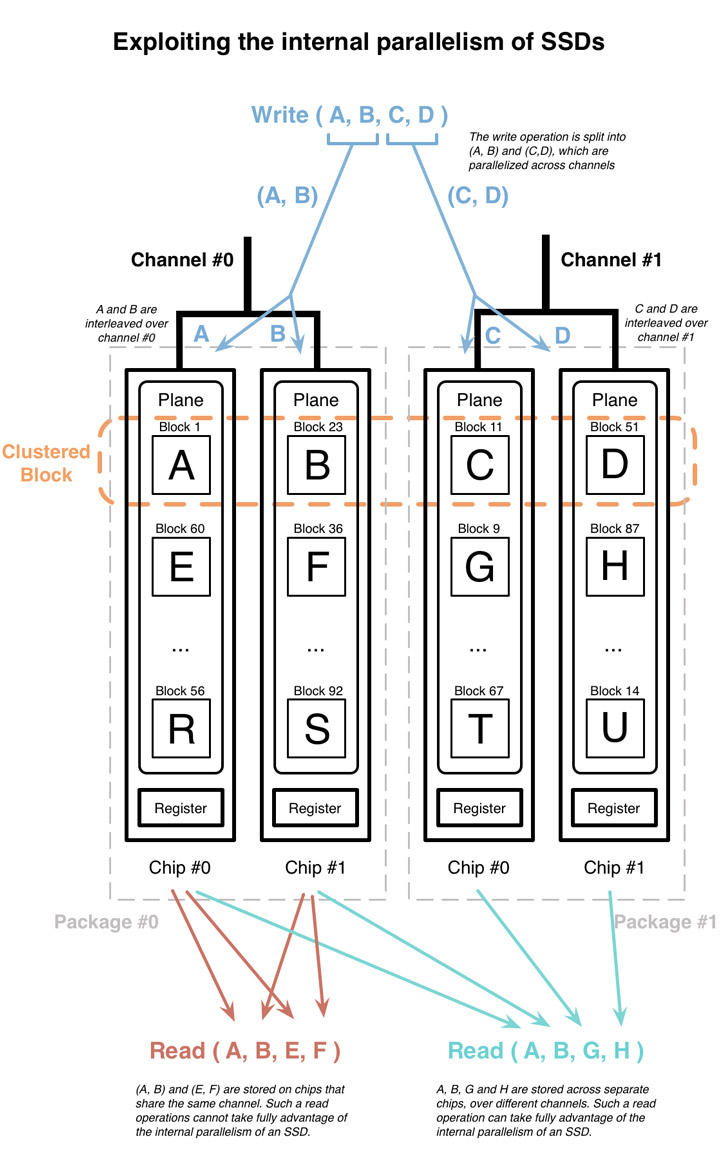
這會直接影響到內部平行機制對應用層讀取資料。因為資料可能剛好在同個 physical channel ,當用多執行緒進行讀取不一定能帶來效能提升。另外在 [3] 也指出多執行緒的讀取會干擾 readahead (prefetchiing buffer) 的運行。
類似 FTL 會先猜你接下來要讀的資料,先抓好放著。
雖然 SSD 廠商通常不公開 page/block/clustered block 大小,但是透過基本的測試工具可以抓出個大概。[2, 3]這些資訊可以用來作為最佳化讀/寫暫存區的大小,並當作分割硬碟的參考依據。
7.4 同時/concurrent 讀寫
[1, 3] 提到交錯讀寫對效能的負面影響,主要是因為讀寫操作同時進行會競爭資源、妨礙 SSD 內部快取、readahead 的運作。 因此作者建議將讀寫活動分開,如果你有 1000 個檔案需要頻繁讀寫,建議一次讀完再一次寫入,而不是讀了又寫讀了又寫讀了又寫...
8. 系統最佳化
8.1 Partition alignment
3.1 提到當除了寫入資料大小是 page 大小倍數之外,寫入位置也要對,否則還是會佔了兩個 physical page。[53]
![from [53]](http://blog.nuclex-games.com/wp-content/uploads/2009/12/ssd-unaligned-write.png) 因此了解 SSD 的 NAND page 大小是很重要滴,想知道如何正確的分割硬碟,可以參考 [54,55]
因此了解 SSD 的 NAND page 大小是很重要滴,想知道如何正確的分割硬碟,可以參考 [54,55]
[54] 壞了 Google 搜尋也可以找到 SSD 型號的相關資料,即便找不到你也可以試著用逆向工程的做法來隔空抓藥[2,3]。
[[43]] 的結果顯示正確的分割磁區對效能有幫助。另外 [44] 也指出跳過/by-passing 檔案系統,直接對硬碟下指令對效能有些微幫助。
8.2 檔案系統參數
5.1 及 [16] 提到的 TRIM 需要從 discard 指令開啟。除此之外拿掉 relatime, 加入 noatime, nodiratime 可能也有幫助。 [40, 55, 56, 57]
8.3 Operating system I/O scheduler
CFQ scheduler (Completely Fair Queuing) 是 linux 預設的 scheduler,他會把 LBA 相近的 IO 放在一起執行,降低 seek 操作的延遲。這種安排對沒有那些會動機構的 SSD 來說並非必要。[56, 58] 以及其他許多的擁護者都建議從 CFQ 換成 NOOP 排程。但從 linux kernel 3.1 開始 CFQ 也有對 SSD 的一些最佳化 [59],另外許多效能評定也指出排程器/scheduler 的效能與搭配的應用層負載及硬碟本身都有關係 [40, 60, 61, 62]。 作者認為除非你的應用層模式固定、並且更改 scheduler 確定有幫助,否則建議還是用預設的 CFQ。
8.4 Swap
swap 把虛擬記憶體 page 寫入硬碟時會帶來大量的 IO 請求,會大幅降低 SSD 壽命。 linux kernel 有個 vm.swappiness 可以設定寫入 swap 的頻率 0-100 由少到多。Ubuntu 的預設是 60,建議設 0 來避免不必要的 swap,提升 SSD 使用年限。另外也有人建議設成 1 ,作者認為基本上是一樣的。[56, 63, 57, 58]
另外也可以用 RAM disk 來做 swap,或是就別用 swap 了。
有點不太懂拿 ramdisk 來做 swap 的意義...
8.5 Temporary files
暫存檔不需要被保存下來,寫到 SSD 去是浪費 P/E cycle 建議可以用 tmpfs,保存在記憶體即可。 [56, 57, 58]
ref
coding for ssd part 5
http://codecapsule.com/2014/02/12/coding-for-ssds-part-5-access-patterns-and-system-optimizations/
其他有編號參考資料請至原文觀賞:link