SSD筆記 - 第三篇 FTL, GC
SSD 學習筆記,翻譯與修訂自 http://codecapsule.com/2014/02/12/coding-for-ssds-part-6-a-summary-what-every-programmer-should-know-about-solid-state-drives/
前情提要
這篇主要介紹 SSD 的讀寫單位如 page、 block,以及寫入放大 (write amplification) 、 wear leveling 等 SSD 問題及設計。除此之外, Flash Translation Layer (FTL) 及其兩個主要功能 logical block mapping, garbage collection (gc)。也以 hybrid log-block mapping 設計當例子介紹 FTL 如何實際進行一個 flash 的寫入操作。
如果是我的筆記會像這樣加註在 info 欄位。
3. SSD 的基本操作
3.1 讀、寫、抹
因為 nand flash 的物理特性, flash memory 存取時必須要遵循特定規則,如果我們了解這些特性對我們在最佳化資料結構設計時會有幫助。
- SSD 讀取以分頁 (page) 為基本單位,即便你只是要讀一個 byte,還是會回傳一個 page。
- 寫入也以 page 為單位,即便你只有寫入小量資料,實際進行物理寫入時 SSD 還是要寫一個 page,此類現象也稱為寫入放大。 write, program 在 SSD 期刊上指的是同一件事。
- copy-modify-write: 已有資料的 page 不能被直接複寫,當需要更改 page 資料時,要不是寫在該 blcok 空白/free 的 page 裡,然後把該 page 標示為 stale,或是將整個 block 複製到 mem 修改,再寫到其他空的 block 去。 stale 的 block 必須在其他時機點清空。
- 資料抹除必須以 block 為單位。一般使用者在讀寫資料時 SSD 不會實際把 stale 資料物理上抹除,SSD也只有進行 read/write 操作。SSD 只在 GC 判斷需要清出空間時對 nand flash 執行抹除/erase 指令。
3.2 寫入範例
圖中得 2 看到我們在寫入 x' 的時候不是複寫 x,而是 free 的 page 1000-3。
3 則是 GC 的操作,把 1000 清為 free,原有資料放到另一個 block,並清除 stale page。

這裡可以猜測 SSD controller 需要很多儲存 lba -> pba 的資料結構.
3.3 寫入放大
寫入小於 page size 的資料會造成 write amplification 的空間浪費([13])[#ref], 寫入 1 B 變成 16 KB。此類寫入放大也會在後續 GC, wear leveling 中持續傳遞。我們也可能寫入一個 page 的資料量但是 address mapping 結果沒有對在 page 開始處,最後要用到兩個 page,並可能觸發 read-modify-write,讓效能變差[2, 5]。
作者給了幾個建議:永遠不要寫入小於一個 page size 的資料,寫入的資料兩大小與 page size 成倍數為原則、小的大量寫入先做緩存再批次寫入。
3.4 wear leveling
因為 SSD cell 有 P/E life cycle 限制,如果我們一直都讀寫同個 block, cell 掛了,SSD 容量會隨著使用一直變少。 wear leveling 就是要讓使用次數平均分配到各個 block 去[12, 14]。 為了做到 wear leveling, controller 在寫入時需要依 page 寫入次數來選擇,必要時也有可能將各個 block 的資料做調動,也是一種 write amplification。 block 管理就是在 wear leveling 跟 write amplification 之間做取捨。 SSD 製造商想出了各種方法來解決這類問題,讓我們繼續看下去。
有點像在整理房間一樣,各個原則都有好有壞 XD。
4 Flash Translation Layer (FTL)
4.1 FTL 的必要性
SSD 可以很快導入是因為他走 HDD 的 Logical Block Addresses (LBA) ,上層軟體/檔案系統不用因為 SSD 做調整。 上面提到SSD 不如 HDD 各個 sector/page 可以直接被複寫,所以 FTL 橫空出世來解決這個問題,把 SSD 操作細節藏起來,讓 host interface 依然只需要對不同的 LBA 做存取,不用管 copy-modify-write, level wearing 等事。
amd64 與 x86 的演進感覺也是類似的關係,向後相容非常重要。誰跟你換個硬體/架構就軟體全部重寫啊 XD。
4.2 LBA to PBA
controller 工作其一就是把 host interface 的 logical block address 轉physical address。這類資料結構通常是存成一個 table ,為了存取效率,這類資料會快取在 controller 的 memory 裡,並提供斷電保護。[1,5]
實作方法有
- page level mapping,最有彈性。每個 page 都對應到各自的 physical page,缺點是需要更大的 ram 來存 mapping table,太貴。
- 為解決上述問題,block level mapping 節省 mapping table 的 ram。整個做法大幅降低了 mapping table ram 用量,但是每次寫入都需要寫入一個 block,面對大量小資寫入放大豈不崩潰[1,2]。
- 上面的 page vs black 的戰爭就是空間換取時間之間的取捨。有些人開始說這樣不行,我全都要:有了混合的 log-block mapping ,面對小資寫入會先寫到 log 緩存區,log存到一定量再合併成 block 寫下去[9, 10]。
下圖是一個簡化版本的 hybrid log-glock FTL 實作。寫了四個 full page 大小的資料,Logical page # 5, 9 都對應到 logicl block number(LBN) 1,此時關聯到一個空的 physical block #1000。 一開始 log-block page mapping table 1、 block #1000 是空的,隨著寫入資料到 block 1000 的過程 physical page offset 會新增/更新其對應位置。 #1000 也稱為 log block。
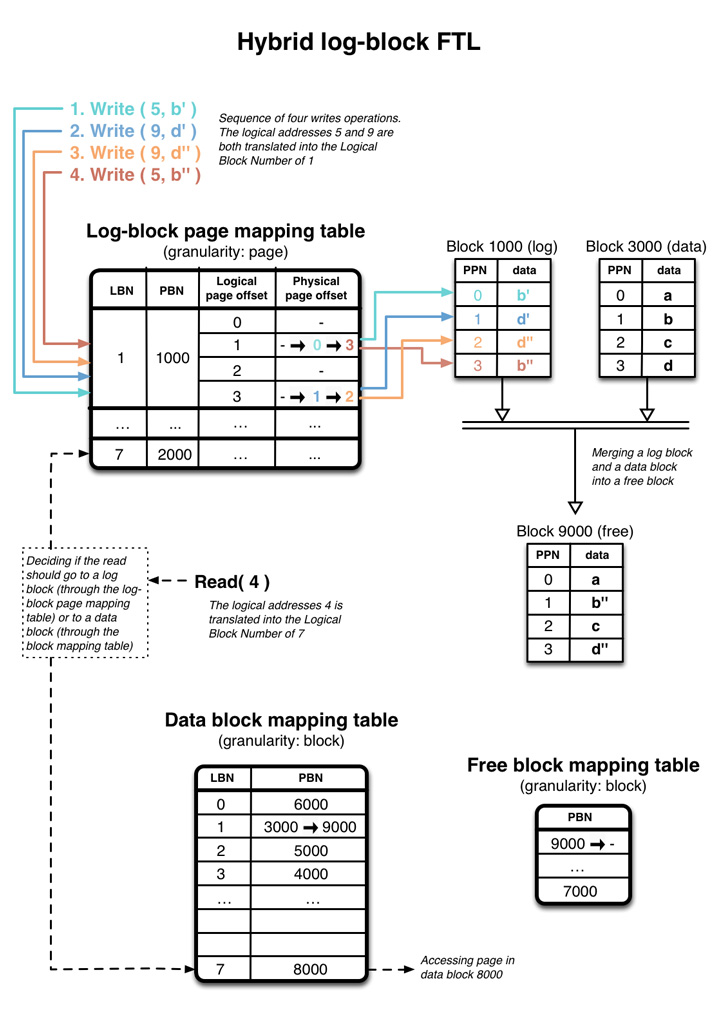
當 log block #1000 寫滿了之後, controller 會將原有的 data block #3000 與 log block #1000 合併,寫到空的 data block #9000,此時 #9000 成了 data block。
值得注意的是這個方法消除了四個寫入 b', d', b'', d'' 可能帶來的寫入放大,而且合併 block 的時候,新的 block #9000 拿到的是新的資料 b'', d''.
最後讀取指令會看現在資料是在 log block 來回傳資料,若否則去查 data-block mapping table(圖左下方)
log-block 在我們剛好寫入完整的 block 的時候也可以直接省去跟 data block 合併的功夫,直接更改 data-block mapping table 的 metadata,並把原有的 data block 清空,更新為 log block。這類最佳化手段也稱為 switch-merge, swap-merge。
目前對 log-block 的研究很多:FAST (Fully Associative Sector Translation), superblock mapping, flexible group mapping [10]。其他的 mapping 手法也有如 Mitsubishi algorithm, SSR [9]。
這類 hybrid log-block 的作法,作者說很像 log-sructured 檔案系統,一個例子是 zfs。 自從 proxmox ve 開始接觸 zfs ,覺得他真的很好用... 從 ubuntu 19.10 開始可以直接把 rootfs 用 zfs 裝喔。
4.3 2014 業界狀況
當時 wikipedia 有 70 間 SSD 廠商, 11 間有能力做 controller, 其中4 間有自有品牌(Intel, Samsung, ...),另外 7 間專做 controller 的公司佔了 90% 的市場銷量[64, 65]。
wiki 上 2019 年變成 12 家,而自有品牌的有 5 間 WD、Toshiba、Samsung、Intel、威盛電子。 台灣的 controller 廠商有 phison, slicon motion, VIA tech, realtek, jmicron
作者不確定是哪幾間公司吃下這個市場,但他以 Pareto(80/20) 法則猜應該是其中的兩三家,所以從除了自有品牌的 SSD,用同一個 controller 大概行為都會差不多。FTL 的實作對效能影響甚鉅,但是各家廠商也不會公開自己用了哪些方法實作。
作者對於了解或是逆向工程[3] mapping schema 的實作對提升應用層程式的效能保持保留態度。畢竟市面上的 controller 廠商大多沒有開放實作細節,就算針對某個 policy 去調整程式設定更甚至你拿到原始碼,這套系統在其他 schema 或是其他廠牌下也不一定有更好的結果。唯一的例外可能是你在開發嵌入式系統,已經確定會用某廠商的晶片。
作者建議大抵上知道許多的 controller FTL 是實作 hybrid log block policy 就好了。然後盡量一次寫入至少一個 block size 的資料,通常會得到較好的結果。
4.4 Garbage Collection
因為將 page 清為 free 的抹除(erase)指令 latency 較高(1500-3500 μs, 寫入 250-1500 μs),大部分的 controller 會在閒暇時做 housekeeping,讓之後寫入作業變快[1],也有一些實作是在寫入時平行進行[13]。
時常會遇到 foregound 頻繁小檔寫入影響 background,導致找不到時間做 GC 的情況。這時候TRIM command, over-provisioning 可以幫得上忙(下一篇會介紹)。
flash 還有一個特性是 read disturb,常讀一個 block 的資料會造成 flash 狀態改變,所以讀了一定次數以後也需要搬動 block [14]
另外當一個 page 裡面有不常改的 cold/static data 及 hot/dynamic data,hot data 的更動會讓他們一起被搬動,分開冷熱資料可以改善這類情況。(不過冷的資料放久了還是會因 wear leveling 被動)。 另外也因為資料冷熱是應用層的事,SSD 不會知道,改善 SSD 效能的一個方法便是冷熱分開在不同的 page裡,讓 GC 好做事。
作者也建議 “非常熱” 的資料可以先 cache 起來再寫到硬碟。以及當有資料不再被需要、或是需要刪除的時候可以批次進行,這讓 GC 可以一次得到比較多的空間操作,降低空間碎片化。
所以很多人提倡電腦換了要把硬碟丟到調理機裡面,這點在 SSD 也不例外 XD
ref
其他有編號參考資料請至原文觀賞:link